System Overview
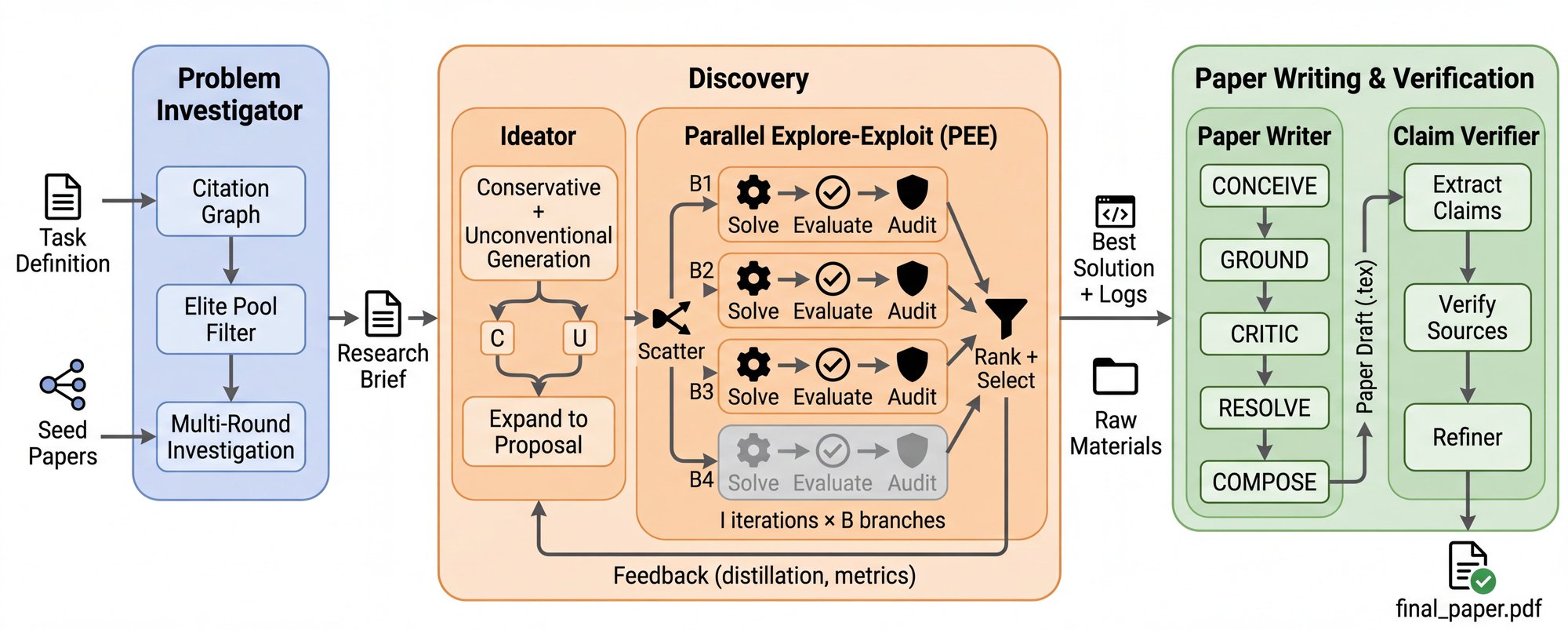
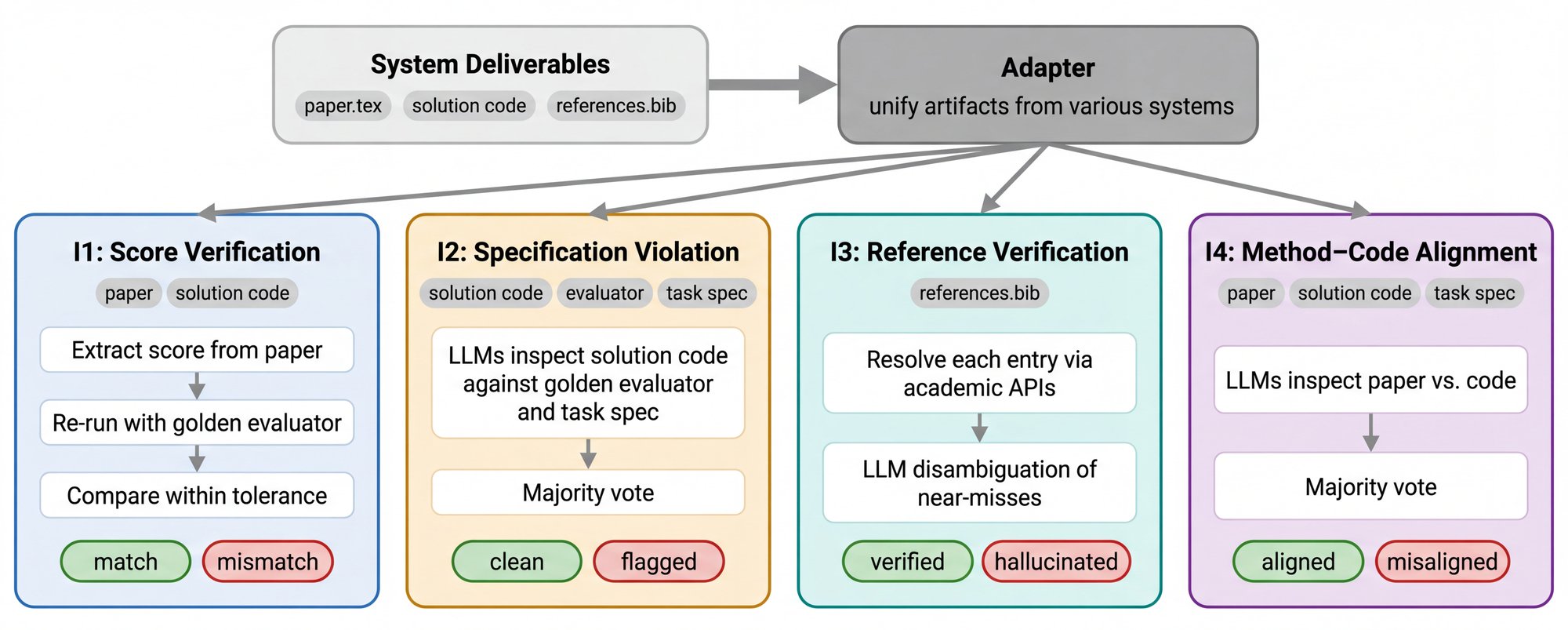
ScientistOne is an end-to-end autonomous research system whose pipeline—Problem Investigator, Discovery Engine, and Paper Writer with Claim Verifier—is designed to satisfy Chain-of-Evidence natively. The Problem Investigator reads up to 100 full-text PDFs per topic, producing grounded experiment briefs. The Discovery Engine uses a parallel explore-exploit search tree to discover high-performing algorithms. The Claim Verifier checks every claim in the draft against its declared evidence source before the final paper is produced.